
ElastiCache の configuration endpoint のフリをする Mimikyu というミドルウェアを作った
Tweet週報 (2019-06 2 週目) | Mimikyu というミドルウェアを書いたり Gato Roboto を一通りクリアしたり のエントリでもチラッと触れたのですが、ElastiCache の configuration endpoint のフリをする Mimikyu というミドルウェアを作ったので、それについて書いていきたいと思います。
実のところ、本番環境には投入することができなかったので実際の環境での利用実績はないです... が、ローカルでテストしたところ、ちゃんと動いているのでどんな環境でもうまく動くはず。
リポジトリは以下のリンクから。
mozamimy/mimikyu: Tiny proxy of ElastiCahce Memceched configuration endpoint
Docker Hub にも Docker イメージを push してあります。
どのようなミドルウェアか
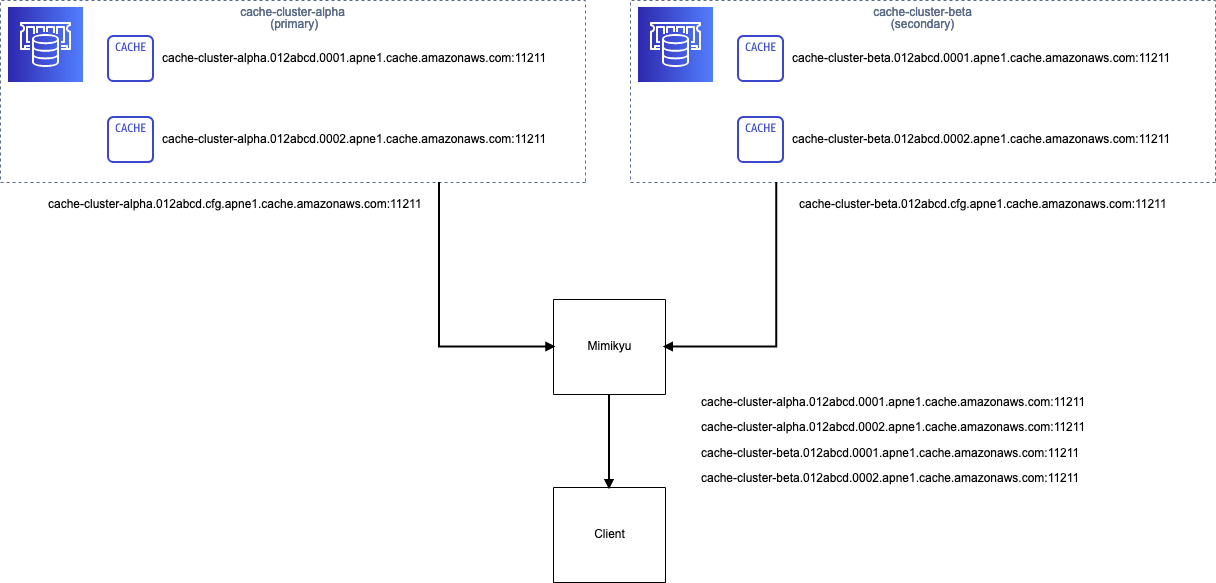
Mimikyu は、TCP ポートで listen し、Mimikyu に接続する Memcached クライアントから見ると configuration endpoint のように振る舞って、上流の 2 つのクラスタに含まれるノードの一覧を結合して返すだけの、一種の Memcached プロキシです。
ElastiCache Memcached では独自の拡張が実装されており、config get cluster というコマンドを受け取ると、そのクラスタに含まれるノードのリストを返すようになっています。ElastiCache に対応した Memcached クライアントは、返ってきたノードのリストをもとにノード一覧を得、各ノードに対して consistent hashing などのアルゴリズムによってキャッシュキーを分散させます。このあたりの話は、公式ドキュメントにも書かれています。
How Auto Discovery Works - Amazon ElastiCache
冒頭の図を例にすると、cache-cluster-alpha と cache-cluster-beta という 2 つのクラスタが存在し、それぞれ 2 つずつのノードが含まれているとき、Mimikyu は両者のノードの情報をマージして 4 つのノードをクライアントに返します。
Mimikyu は stats コマンドと config get cluster コマンドのみに反応し、それ以外のコマンドが発行された場合には SERVER_ERROR を返して接続を切ります。stats コマンドはプライマリのクラスタにプロキシしますが、プライマリが存在しない、またはノードがダウンしている場合にはセカンダリから取得してプロキシします。
Mimikyu のつかいどき
ElastiCache のクラスタ間のマイグレーション
そもそもこれを作るきっかけになったのは、2 つの ElastiCache クラスタ間でマイグレーションを行いたいという要求でした。ですので、そのような場合に使うことを想定しています。
ElastiCache Memcached を利用しているアプリケーションにおいて、Memcached ノードのスケールアウト/スケールインは、それぞれクラスタ中のノードを追加/削除するだけで済むので簡単です。
もちろん、Memcached クライアントが consistent hashing などを使っていてまともにクラスタとして扱えていて、再接続なども上手にやれているという前提はつきますが、ポピュラーな言語でデファクトスタンダードになっているクライアントはだいたいまともな実装になっていることでしょう。たとえば Ruby だと dalli が有名ですが、運用上でのトラブルもなく堅牢だと感じています。
問題となるのは、Memcached ノードのスケールイン/スケールアップ、つまり、クラスタのノードタイプそのものを変更したい場合です。たとえば、リリース当初の見積もりよりも小さななキャパシティで済みそうな場合、コストを最適化するためにより小さなノードタイプを使いたいですよね。AWS 公式のドキュメントにも、このような場合には新しいクラスタを作りましょうとあります。
キャッシュが一時的に空になっても耐えられそうな場合は、アプリケーションからの Memcached の向き先を新しいクラスタに向けて一気に切り替えてもよいですが、キャッシュに強く依存しているアプリケーションや、キャッシュが一時的に空になったときの影響が予測しにくい場合には、これでは困ってしまいます。利用の少ない時間帯に切り替えるというのも手ですが、オフピークが深夜のアプリケーションだと深夜メンテナンスを行う必要があり、それはできる限り避けたいですよね。
クラスタ間のマイグレーションで Mimikyu を使う
そこで、Mimikyu を ECS なり Kubernetes なり EC2 インスタンスなり、適当な方法でデプロイしてアプリケーションの Memcached の向き先を Mimikyu に向けることで、アプリケーションからは、一時的にマイグレーション元のノードとマイグレーション先のノードがすべてディスカバリされます。
この状態からマイグレーション元のノードを様子を見つつ落としていくことで、キャッシュが無効になるショックを和らげつつ、最終的にマイグレーション先のクラスタのノードのみが残った状態になります。あとはアプリケーションの Memcached の向き先をマイグレーション先のクラスタの configuration endpoint に変えれば切り替えが完了になります。
新旧両方の configuration endpoint に接続してノード一覧をマージするようにアプリケーションコードを書き換えることでも実現できますが、Mimikyu を使えば、接続先を変えるだけなのでアプリケーションの実装を書き換えなくて済むというメリットがあります。
制限事項
とりあえず dalli-elasticahce で使えればよかろうということで突貫工事で実装してるので、他のクライアントからうまく使えるかは検証できてないですが、どれも似たような実装になっているはずなのでそのまま使えるかなという気持ちです。バイナリプロトコルもしゃべれません。