
Redis の無停止マイグレーションと ElastiCache そして Redis Sentinel
Tweetやんごとなき事情により、CentOS 6 が動く古いサーバをつぶしていくというようなことを普段やっていて、Cent OS 6 上で動く Redis をどのように移行しようか、ということを最近考える機会があったので、このエントリにメモしておきます。
オンプレミスではなく AWS の EC2 や ElastiCache に寄せていくということと、Redis を利用するアプリケーションサーバでは Ruby on Rails が動いているという暗黙の前提があるため、そのつもりで読んでいただければと思います。
無停止で Redis サーバをマイグレーションすることの困難さ
Ubuntu 16.04 用に Redis サーバを準備するのはそれほど大変な作業ではありません。キャパシティプランニングさえ終えれば、あとはちょっと Itamae や Chef のレシピを書いてやるだけ、です。
問題は切り替え方法です。アプリケーションをメンテ状態にできるなら一番簡単です。しかし、たとえば会社の根幹をなすような重要なサービスであったりすると、様々な部署との調整も発生しますし、おいそれと止めるわけにはいかないでしょう。
ただし、明示的にメンテナンス状態にせずとも、切り替え中のエラーはある程度許容する、というポリシーで切り替えることは可能です。たとえば、10 秒ほどならば 5xx が返る期間があっても、それは必要な対価として受け入れられるでしょう。それが数十分となると、許容することはできないかもしれませんが..。
このように、いかにダウンタイムをゼロに近づけつつシュッと切り替えられるかが SRE の経験が生きてくるところでしょう。というわけで、動き続けている Redis を新しいサーバに移すために、どのような方法があるのかを考えていきます。
レプリケーションによる(ほぼ)無停止マイグレーション
プラットフォームとして AWS を利用している場合、一般的に要件を満たすならばなるべくマネージドサービスに寄せていくほうがメンテナンスコストが下がってよいでしょう。そこで、最初に候補に上がるのが ElastiCache Redis です。条件付きですが (後述)、multi-az 間での自動フェイルオーバーが可能で、ElastiCache を使うことができれば運用不可がぐっと下がるため、できれば使っていきたいところです。
あれこれ考えた結果、ElastiCache への無停止マイグレーションは困難、という結論に落ち着きました。
今回のようなケースだと、master にはすでに VIP がついているため、以下の図のような手順でほぼ無停止マイグレーションが可能です。
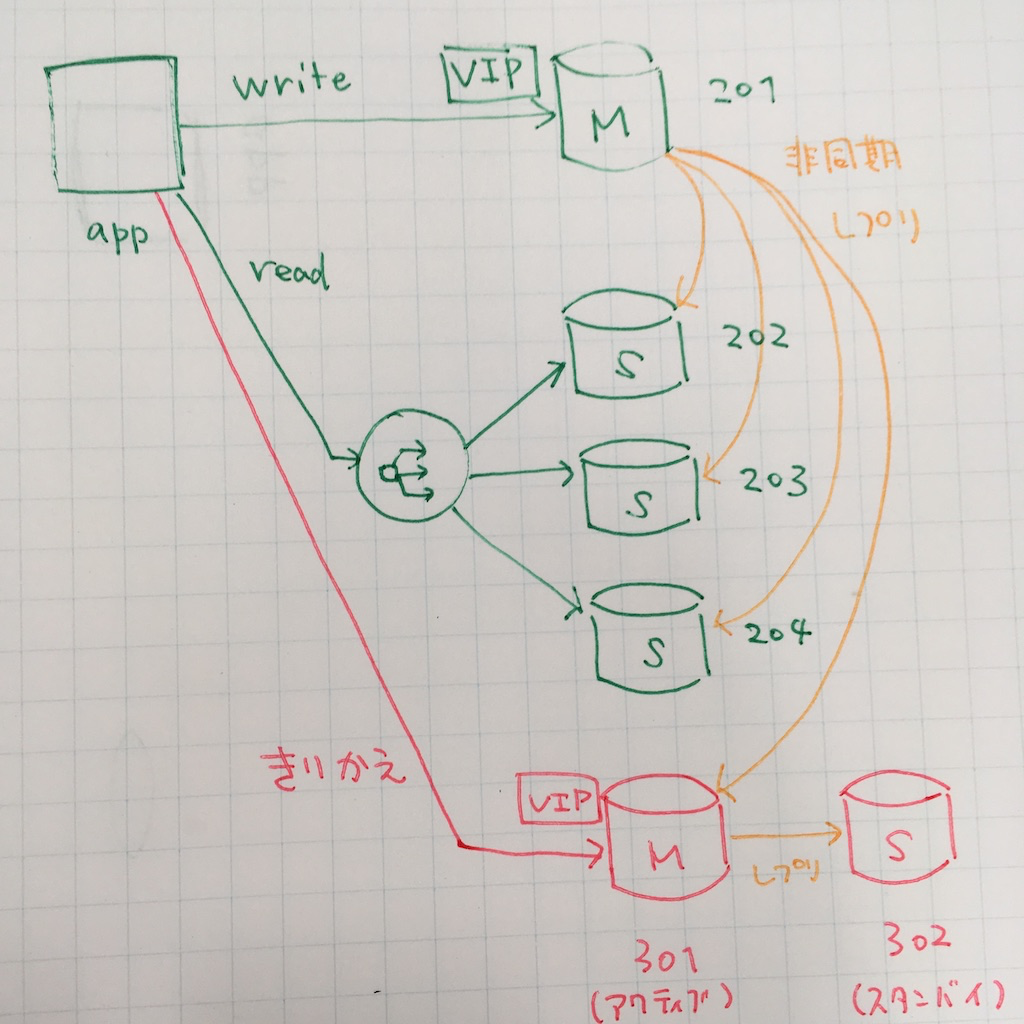
app はアプリケーションサーバ群、201~204 は現在動いている旧 Redis インスタンス、301 および 302 は移行先の新しい Redis のインスタンスであるとします。
今回は計 4 台のレプリケーショングループとして動く旧 Redis インスタンスを、リソースの状況を見たところ 1 台でまかなえそうなため、1 台の Redis を active/standby 構成にし、そちらに切り替えるという例を見ていきます。
- 初期状態
- app が VIP を通じて master に write、slave への read は ELB で分散。201 -> 202,203,204 に対して非同期レプリケーションしている
- 新しい Redis サーバを用意する
- リソースの利用状況を考えると read/write ともに一台のサーバでまかなえそうなので、301 をアクティブ、302 をスタンバイ構成にする
- 201 から 301 にレプリケーションされるようにし、301 から 302 へレプリケーションされるようにする
- HA 構成にするために Pacemaker あるいは Redis Sentinel (後述) や Redis Cluster を使う
- アプリケーションの Redis の設定を更新し、slave として 301 を指定してデプロイ
- 問題ないかしばらく観察する
- アプリケーションの Redis の設定を更新し、master として 301 を指定してデプロイ
- 以降先が EC2 なら単純に VIP を切り替えるだけでもよい
この切替方法は、ElastiCache を移行先に選んだ場合には不可能になります。なぜなら、ElastiCache Redis のインスタンスでは SLACEOF コマンドが利用できず、201 の slave としてぶら下げることができないからです。(参考: 制限されるコマンド - Amazon ElastiCache)
余談: ElastiCache の t2 インスタンスの自動フェイルオーバ
ElastiCache Redis には非クラスターモードとクラスターモードという 2 種類の扱い方があり、非クラスターモードはクラスタという概念がない素の Redis に無理やり(?)クラスタっぽい扱い方をしているモードで、ElasiCache Redis がリリースされた当時から存在するモードです。対するクラスターモードは、文字通り Redis Cluster をバックエンドにしているモードで、シャーディングなどがサポートされたちゃんとしたクラスターです。
クラスターモードについては以下の公式ドキュメントがわかりやすいです。
- ElastiCache クラスター - Amazon ElastiCache
- レプリケーション: Redis (クラスターモードが無効) と Redis (クラスターモードが有効) - Amazon ElastiCache
公式ドキュメントにあるように両者にはいろいろと違いがあるのですが、上述のページに書かれていない地味に便利そうなポイントとして、クラスターモードの場合は t2 インスタンスでも自動フェイルオーバを有効にできる、ということがあります。対する非クラスターモードでは、cache.m3.medium 以上のインスタンスタイプでないと自動フェイルオーバを有効にできないという制限があります。
「じゃあ m3 にすればええやん!」と思われるかもしれませんが、マイクロサービス化や ECS & Hako で新規アプリケーションの立ち上げが増えている今、新たな Redis が必要だが m3 だとオーバースペックだ、というようなシチュエーションが実際に発生しています。コスト面を考えると、t2 で済むならそれを使っていきたいのです。
クラスターモードだとややこしくなると思われるかもしれませんが、シャード数を 1 に設定しレプリカを 1 に設定すれば、クラスターモードが無効で primary 1 台、replica 1 台で構成した場合とほぼ同じような構成になります。
ただし、Rails から利用することを考えると現状クラスターモードは使いものにならず、t2 インスタンスで自動フェイルオーバを組むことはできません。なぜなら、Redis Cluster を使うためにはクライアントが Redis Cluster に対応している必要があるからです。
Ruby 界隈ではいわゆる Redis gem がデファクトスタンダードです。2017-11-05 現在、この gem では Redis Cluster に対応しておらず、PR 上でレビューされているという状態のようです (Add Redis Cluster support by supercaracal · Pull Request #716 · redis/redis-rb)。というわけで、Rails アプリケーションから Redis Cluster を使うことができるようになるのは、もう少し先の話となりそうです。
Redis Sentinel で HA 構成
というわけで、ElastiCache Redis を使うことはあきらめて、Redis on EC2 (Ubuntu 16.04) に移行することにしました。
次に考えることは、どのようにして HA 構成にするかという点です。ElastiCache だと multi-az での自動フェイルオーバを簡単に使うことができるので何も考えなくてよいですが、EC2 に Redis をのせるならば自前で自動フェイルオーバを組む必要があります。
自動フェイルオーバできるようにするためにはいくつかのやり方が考えられます。今回は 2 台の Redis を active/standby 構成にすることを考えます。
- Pacemaker や Heartbeat を使って、相方が死んだら VIP を切り替えるのを自前でやる (古典的)
- Redis Sentinel を使う
- Redis Cluster を自前で組む
このうち、Redis Cluster は真っ先に候補から外れます。なぜなら、余談にも書いたように Redis gem が Redis Cluster をサポートしていないからです。
Pacemaker や Heartbeat を使うやり方では、slave を master に昇格したときにアプリが書き込みたいデータのロストを最小にする、split brain に陥らないようにどうにかする、などなどの工夫を自前で全てやる必要があります。最近 本当は恐ろしい分散システムの話 というスライドが話題になっていましたが、Redis 作者の「ユーザお手製のスクリプトで同じような事をするよりは依然として 99% マシな選択肢である」という言葉の通り、Redis Sentinel や Redis Cluster という選択肢がある今、あまり良手ではないでしょう。
というわけで、Redis Sentinel を実戦投入したいなと思って、ドキュメントを読みつつちょっと手を動かして検証してみました。以下は Redis Sentinel Documentation – Redis を読んで理解したことの要約に、わたしの思うところをちょい足ししたような文章になっています。
Redis Sentinel でできること
- モニタリング: master と slave が期待通りに動いているかを監視できる。
- 通知: API を通じて監視しているインスタンスに異常が起こったときに通知できる。
- 自動フェイルオーバ: master がダウンしたときに slave を master に昇格できる。
- Configuration provider: サービスディスカバリとして動作し、Sentinel に接続しているクライアントに master の情報 (IP アドレスとポート) を知らせることができる。
つまり、Sentinel を使えば自動フェイルオーバが可能などころか、クライアントが Sentinel に対応していれば VIP の付け替えなどの仕組みを用意せずとも、フェイルオーバ後の master に再接続させることができる、ということです。ただし、Redis では非同期レプリケーションとなるため、ある程度のデータロスト (書き込んだはずのデータが書き込まれない) は許容し、そうなっても問題ないようにアプリケーションを作る必要があります (軽減する方法はあります)。
Redis Sentinel は分散システムである
Redis Sentinel は分散システムであり、それ自体がクラスタです。どのような故障クラスにも耐えうるわけではないですが、適切に構成できれば、Sentinel 自身に相応に十分な耐故障性をもたせられる上、誤検知による不必要なフェイルオーバが始まってしまう確率を減らすことができます。
Sentinel によるフェイルオーバは、ざっくり以下のような感じで動きます。
- quorum に設定した数以上の Sentinel が master がダウンしたと判断した場合に、Sentinel 全体として「その master はダウンした」と合意する。
- 多数決によるリーダー選出を行い、フェイルオーバをするために動く Sentinel をひとり選ぶ。
- ^ で選ばれた Sentinel が適切だと思われる slave をひとり選び、master に昇格するように設定を再構成する。
- Sentinel に接続しているクライアントは master が切り替わったことを検知し、書き込みを新 master に向ける。
quorum は好きな数を設定することができます。quorum を小さく設定することで素早くフェイルオーバを開始できる代わりに、誤検知の可能性も増えるでしょう。逆に quorum を大きく設定することにより、フェイルオーバが遅くなる代わりに誤検知の可能性を減らすことができます。
ここで注意すべきは、フェイルオーバを実行するために多数決によるリーダー選出が行われる、というところです。つまり、Sentinel 全体で過半数のノードが死んでしまっている場合、残念ながら自動フェイルオーバが実行されることはありません。
たとえば 5 コの Sentinel プロセスがあり、quorum が 2 に設定されていると、以下のように動作します。
- もし 2 コ以上の Sentinel がある master がダウンしたと判定したらフェイルオーバのプロセスを開始する。
- もし 3 コ以上の Sentinel が生きていれば、多数決合意により選出されたリーダーがフェイルオーバの処理を行う。
Sentinel クラスタの構成例
Example 1: just two Sentinels, DON'T DO THIS
ドキュメントにはいくつかの構成例が載っています。たとえば、Example 1 はこんな感じです。
+----+ +----+
| M1 |---------| R1 |
| S1 | | S2 |
+----+ +----+
Configuration: quorum = 1
四角はボックス、つまり 1 台のインスタンスを示しており、その中で Redis インスタンスが動いています。M1 は master、R1 は slave (R は replica の R) で、S1 および S2 は Sentinel プロセスたちです。
分散システムをかじったことのある人なら、この図をみただけで「あっ・・・」という感じでニンマリできることでしょう。この構成では左のインスタンスと右のインスタンスの接続が切れると split brain に陥り、悲しいことになってしまいます。
+----+ +------+
| M1 |----//-----| [M1] |
| S1 | | S2 |
+----+ +------+
S2 は M1 がダウンしたと検知して右のインスタンスの Redis を master に昇格しますが、左のインスタンスも依然自分を master だと思っているので、一つのレプリケーショングループの中で master がふたりになってしまいました。試合終了です。
Example 2: basic setup with three boxes
+----+
| M1 |
| S1 |
+----+
|
+----+ | +----+
| R2 |----+----| R3 |
| S2 | | S3 |
+----+ +----+
Configuration: quorum = 2
Example 1 で見たように、典型的な split brain を避けるために Sentinel クラスタには最低でも 3 コ以上のインスタンスが必要です。これは分散システムに一般的なことで、Elsticsearch なども 3 台以上で構成することが普通です。Example 2 は quorum = 2 かつ過半数が 2 なので、1 台のクラッシュまでなら Sentinel は正しく動作することができます。
ただし、以下のような状態に陥ることがあるので注意が必要なパターンです。
+----+
| M1 |
| S1 | <- C1 (writes will be lost)
+----+
|
/
/
+------+ | +----+
| [M2] |----+----| R3 |
| S2 | | S3 |
+------+ +----+
もし M1 からのびている接続が切れてネットワークが分断されてしまった状態になると、S2 と S3 で合意してどちらかのインスタンスが master に昇格します。この図では R2 が昇格しました。ただし、もし M1 に書き込んでいるクライアント C1 が M1 と同じ分断されたネットワークに存在して M2 と R3 から分断されてしまった場合、C1 は M1 に対してネットワークが回復するまで健気に書き込み続けることになり、その間のデータはロストします。ネットワークが回復すると M1 は slave に降格しますが、分断が起こってからこの間に書き込まれたデータは全て失われます。
このようなデータロストを少しでも軽減するために、このような構成をとる場合は、master に以下のような設定を書いておくことが推奨されます。
min-slaves-to-write 1
min-slaves-max-lag 10
これは「2 台の slave と接続が 10 秒以上切断されていた場合に書き込みを禁止する」というような設定です。min-slaves-to-write 1 は master に書き込むためには最低 1 台の slave が存在していなければならない、という意味です。このようにしておくことで、上述のパターンでは最大 10 秒間の書き込みはロストしますが、それ以降のロストは防ぐことができます。ただし、この場合 slave が 2 台ともダウンすると Sentinel は機能しなくなりますし、M1 へ書き込むこともできなくなるため、レプリケーショングループ全体として完全にダウンした状態になることは避けられません。これはトレードオフです。
その他の Example
Example 3 ではクライアント側に Sentinel を持たせる例で、Example 4 は master/slave を 1 台ずつにして Sentinel を同居させたいが、それでは典型的な split brain に陥るためクライアントにも Sentinel を持たせる、というようなパターンです。
結局どういう構成にすればいいの?
これらの Example にあるように、Sentinel の構成パターンは様々で、それぞれにメリットデメリットがあります。そして、Example では紹介されていませんが、ひとつの Sentinel クラスタで複数の master を監視することもできるため、Sentinel だけが動くインスタンスを複数用意してクラスタリングし、複数のレプリケーショングループを監視させるという構成も考えられます。
わたしは Sentinel が Redis やクライアントと同居しているよりも、Sentinel だけが動く小さい t2 インスタンスを複数の AZ にまたがって 3 コ以上並べてクラスタリングするがいいかなと思っており、実戦投入するならばそのような構成にしようと思っています。レプリケーショングループごとに Sentinel クラスタが存在するのは煩雑ですし、そもそも active/standby 構成にすると 2 台になるので、split brain になる危険性があります。かといってクライアントに Sentinel を持たせるにしても、app および app-pantry はオートスケーリングによって増減するため、quorum をどうやって設定するねん、というような問題も出る上、Rails と同居するミドルウェアが増えるのも少しいやです。
やってみた
習うより慣れろ、というわけで、Sentinel を手元の Mac で試してみました。ドキュメントの「A quick tutorial」の内容をもう少し具体的に書いていきます。
このチュートリアルでは、手元のマシンのポート 6379 および 6380 でそれぞれ Redis の master と slave を listen させ、Sentinel はそれぞれポート 5000、5001、5002 で listen させます。
まず、Redis の設定を /opt/brew/etc/redis.conf などから適当な作業ディレクトリに redis.mster.conf および redis.slave.conf のような名前でコピーし、redis.slave.conf の port を 6780 にして 2 コの Redis を起動します。
$ redis-server redis.master.conf
$ redis-server redis.slave.conf
次に、レプリケーションを組むために slave で SLAVEOF コマンドを発行します。
$ redis-cli -p 6380 slaveof 127.0.0.1 6379
レプリケーションが行われているかどうか、適当に値を突っ込んで試してみましょう。
$ redis-cli -p 6379 set usausa pyonpyon
$ redis-cli -p 6380 get usausa
次に Sentinel を起動します。最小の設定は以下のようになります。
port 5000
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
一番のポイントは sentinel monitor mymaster 127.0.0.1 6379 2 の部分で、最後の 2 は quorum を表します。つまり、この場合だと 3 コの Sentinel のうち 2 コの Sentinel が master のダウンを検出したらフェイルオーバのプロセスが始まることになります。down-after-milliseconds の部分は、5 秒間 PING コマンドの応答がなければ master がダウンしたと判定するという設定です。
同様に port を 5001 および 5002 に設定したファイルを作り、それぞれ sentinel_alpha.conf、sentinel_beta.conf、sentinel_gamma.conf のようなファイル名で保存し、以下のようにして 3 コの Sentinel を起動します。
$ redis-sentinel sentinel_alpha.conf
$ redis-sentinel sentinel_beta.conf
$ redis-sentinel sentinel_gamma.conf
Sentinel のログを観察すると、以下のように beta と gamma をディスカバリしていることがわかります。
[14:11:05]mozamimy@P861:test-sentinel (test-sentinel) (-'x'-).oO(
(ins)> redis-sentinel sentinel_alpha.conf
# :
# : 中略
# :
89368:X 02 Nov 14:11:11.519 # Sentinel ID is 499d72ec25403cd130e564ad5db173a915ead877
89368:X 02 Nov 14:11:11.519 # +monitor master mymaster 127.0.0.1 6379 quorum 2
89368:X 02 Nov 14:11:11.521 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
89368:X 02 Nov 14:11:28.646 * +sentinel sentinel ec1ba6adead03f1a6ce73c29545290192fc4a519 127.0.0.1 5001 @ mymaster 127.0.0.1 6379
89368:X 02 Nov 14:11:40.176 * +sentinel sentinel 0d06cbe31776185b622cfbd901e099523e4f753e 127.0.0.1 5002 @ mymaster 127.0.0.1 6379
ここでは、以下のように Sentinel ID が割り当てられました。
- alpha(5000): 499d72ec25403cd130e564ad5db173a915ead877
- beta(5001): ec1ba6adead03f1a6ce73c29545290192fc4a519
- gamma(5002): 0d06cbe31776185b622cfbd901e099523e4f753e
次に、検証用の Redis クライアントプログラムをサクッと書きます。今回は Rails から使うことを想定しているので、以下のように Ruby でサクッと書いてみました。
require 'redis' require 'logger' require 'securerandom' INTERVAL = 0.3 SENTINELS = [ { host: '127.0.0.1', port: 5000 }, { host: '127.0.0.1', port: 5001 }, { host: '127.0.0.1', port: 5002 }, ] redis = Redis.new( url: 'redis://mymaster', sentinels: SENTINELS, role: :master, ) logger = Logger.new(STDOUT) loop do begin key = SecureRandom.uuid redis.set(key, "value: #{key}") logger.info("Set: #{key}") sleep 0.3 rescue => e logger.error(e) end end
Redis gem は Sentinel に対応しているため、Redis インスタンスを初期化するときに sentinels に Sentinel の情報を渡すことでフェイルオーバにより master が入れ替わったことを検知することができます。
では、以下のようにしてこのスクリプトを動かしましょう。ここまでの設定がうまくいっていれば、以下のように無限に Redis に書き込みを行う様子が観測できるでしょう。
[14:35:12]mozamimy@P861:test-sentinel (test-sentinel) (-'x'-).oO(
(cmd)> be ruby redis_test.rb
I, [2017-11-02T14:35:27.158469 #90793] INFO -- : Set: 17aadea4-fb75-4518-916c-b22fbfbbb00f
I, [2017-11-02T14:35:27.460865 #90793] INFO -- : Set: 2a193421-4ee7-4d43-8491-4c8886a0dfba
I, [2017-11-02T14:35:27.765881 #90793] INFO -- : Set: 89def42a-ae8f-45f6-bfaf-b2db90ec3834
I, [2017-11-02T14:35:28.070549 #90793] INFO -- : Set: 4fe43824-b17d-43f4-a5f0-5ba28c63609a
Sentinel に対して SENTINEL コマンドを get-master-addr-by-name オプションとともに発行することにより、現在の master を問い合わせることができます。
$ redis-cli -p 5000 sentinel get-master-addr-by-name mymaster
1) "127.0.0.1"
2) "6379"
では、実際に master を止めてフェイルオーバさせてみます。
$ redis-cli -p 6379 debug sleep 30
DEBUG コマンドを sleep オプションとともに使うことにより Redis サーバをスリープさせることができます。スリープすると PING コマンドにも反応しなくなるため、Sentinel からは死んだように見えます。
すると、Sentinel (alpha) では以下のようなログが流れてフェイルオーバのプロセスが進みます。
89368:X 02 Nov 14:21:48.197 # +sdown master mymaster 127.0.0.1 6379
89368:X 02 Nov 14:21:48.298 # +new-epoch 1
89368:X 02 Nov 14:21:48.299 # +vote-for-leader ec1ba6adead03f1a6ce73c29545290192fc4a519 1
89368:X 02 Nov 14:21:49.294 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2
89368:X 02 Nov 14:21:49.294 # Next failover delay: I will not start a failover before Thu Nov 2 14:23:48 2017
89368:X 02 Nov 14:21:49.429 # +config-update-from sentinel ec1ba6adead03f1a6ce73c29545290192fc4a519 127.0.0.1 5001 @ mymaster 127.0.0.1 6379
89368:X 02 Nov 14:21:49.429 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380
alpha は master のダウンを検知し、master のステータスを SDOWN としてマークしました。それと同時に vote-for-leader というログからもわかるように、リーダとして ec1ba6adead03f1a6ce73c29545290192fc4a519、つまり beta に投票しています。やがて quorum の充足数を満たし、master は ODOWN としてマークされます。
ここでは beta がリーダーとして選ばれたので、beta が「オッ」と言いながらフェイルオーバを行います。
89371:X 02 Nov 14:21:48.238 # +sdown master mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:48.294 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2
89371:X 02 Nov 14:21:48.294 # +new-epoch 1
89371:X 02 Nov 14:21:48.294 # +try-failover master mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:48.297 # +vote-for-leader ec1ba6adead03f1a6ce73c29545290192fc4a519 1
89371:X 02 Nov 14:21:48.299 # 0d06cbe31776185b622cfbd901e099523e4f753e voted for ec1ba6adead03f1a6ce73c29545290192fc4a519 1
89371:X 02 Nov 14:21:48.299 # 499d72ec25403cd130e564ad5db173a915ead877 voted for ec1ba6adead03f1a6ce73c29545290192fc4a519 1
89371:X 02 Nov 14:21:48.350 # +elected-leader master mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:48.350 # +failover-state-select-slave master mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:48.427 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:48.427 * +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:48.527 * +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:49.329 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:49.329 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:49.426 # +failover-end master mymaster 127.0.0.1 6379
89371:X 02 Nov 14:21:49.426 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380
正常にフェイルオーバが行われると、以下のように 6380 で listen している Redis が master であると報告するようになります。
$ redis-cli -p 5000 sentinel get-master-addr-by-name mymaster
1) "127.0.0.1"
2) "6380"
検証用のスクリプトのログを見ると、約 20 秒で復帰していることがわかります。
# :
$ : 中略
# :
I, [2017-11-02T14:37:18.586785 #90793] INFO -- : Set: a161a0ff-129c-4f01-979c-63f68c043120
I, [2017-11-02T14:37:18.892121 #90793] INFO -- : Set: 3efe28e7-f4ae-4224-968e-1c5404dae0bb
I, [2017-11-02T14:37:19.197081 #90793] INFO -- : Set: 0a65a3e3-74bd-4af4-aba8-c99455638d99
E, [2017-11-02T14:37:29.507734 #90793] ERROR -- : Connection timed out (Redis::TimeoutError)
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:71:in `rescue in _read_from_socket'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:64:in `_read_from_socket'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:56:in `gets'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:360:in `read'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:260:in `block in read'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:248:in `io'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:259:in `read'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:118:in `block in call'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:229:in `block (2 levels) in process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:366:in `ensure_connected'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:219:in `block in process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:304:in `logging'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:218:in `process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:118:in `call'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:524:in `check'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:103:in `block in connect'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:291:in `with_reconnect'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:98:in `connect'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:363:in `ensure_connected'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:219:in `block in process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:304:in `logging'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:218:in `process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:118:in `call'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:783:in `block in set'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:45:in `block in synchronize'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/2.4.0/monitor.rb:214:in `mon_synchronize'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:45:in `synchronize'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:779:in `set'
redis_test.rb:25:in `block in <main>'
redis_test.rb:21:in `loop'
redis_test.rb:21:in `<main>'
E, [2017-11-02T14:37:39.515995 #90793] ERROR -- : Connection timed out (Redis::TimeoutError)
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:71:in `rescue in _read_from_socket'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:64:in `_read_from_socket'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:56:in `gets'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/connection/ruby.rb:360:in `read'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:260:in `block in read'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:248:in `io'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:259:in `read'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:118:in `block in call'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:229:in `block (2 levels) in process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:366:in `ensure_connected'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:219:in `block in process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:304:in `logging'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:218:in `process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:118:in `call'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:524:in `check'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:103:in `block in connect'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:291:in `with_reconnect'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:98:in `connect'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:363:in `ensure_connected'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:219:in `block in process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:304:in `logging'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:218:in `process'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis/client.rb:118:in `call'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:783:in `block in set'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:45:in `block in synchronize'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/2.4.0/monitor.rb:214:in `mon_synchronize'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:45:in `synchronize'
/Users/mozamimy/.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/redis-4.0.1/lib/redis.rb:779:in `set'
redis_test.rb:25:in `block in <main>'
redis_test.rb:21:in `loop'
redis_test.rb:21:in `<main>'
I, [2017-11-02T14:37:49.497914 #90793] INFO -- : Set: 6369049b-c3c6-44ed-ac48-b90064512797
I, [2017-11-02T14:37:49.803051 #90793] INFO -- : Set: aa34666a-b3de-40a1-bc9c-4cae96b8002b
I, [2017-11-02T14:37:50.106556 #90793] INFO -- : Set: 6b2ddd15-1668-4012-87cf-fbcabc26d570
# :
# : 中略
# :
また、6379 の Redis に sleep を入れてから 30 秒たつと Sentinel は 6379 の Redis の回復を検知して、6380 の slave として 6379 をぶら下げます。
ここまで見てきたように、クライアントが Redis Sentinel に対応していれば、お手軽に Redis を HA 構成にできるのですごく便利そうです。
Sentinel は状態を設定ファイルに持つ
とても便利そうな Sentinel ですが、イマイチポイントもあります。たとえば、Sentinel は状態を設定ファイル内に持つため、時々で設定ファイルをゴリゴリに書き換えます。つまり、Itamae のようなプロビジョニングツールと非常に相性が悪いのです。以下は、何回かフェイルオーバさせたあとの sentinel_alpha.conf の様子です。設定をバージョンニングするための config-epoch や leader-epoch のような値が書き込まれていたりするのがわかります。
port 5000
sentinel myid 499d72ec25403cd130e564ad5db173a915ead877
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
# Generated by CONFIG REWRITE
dir "/Users/mozamimy/var/repo/ckpd/zatsu-scripts/infra/test-sentinel"
sentinel config-epoch mymaster 2
sentinel leader-epoch mymaster 3
sentinel known-slave mymaster 127.0.0.1 6380
sentinel known-sentinel mymaster 127.0.0.1 5002 0d06cbe31776185b622cfbd901e099523e4f753e
sentinel known-sentinel mymaster 127.0.0.1 5001 ec1ba6adead03f1a6ce73c29545290192fc4a519
sentinel current-epoch 3
一般的に、分散システムでは状態は設定ファイルとは別に持ちますが、何を思ったのか Sentinel ではそうなっていないようです。そのため、設定ファイルは設定ではなく状態として割り切って扱い、Itamae の管理対象から外すようにしないといけなさそうです。
まとめ
Redis サーバの以降の話から、ElasiCache Redis と Redis Sentinel でちまちま検証した結果を書いてきました。その結果、EC2 で Redis を HA 構成にするならば、Redis Sentinel は筋が良さそうだという感触を得ることができました。ここで得た知見が参考になれば幸いです。