
Elasticsearch 5.x & Kibana 5 に移行したときになぜか棒が分割できない問題に対処したメモ
Tweet古いバージョンの EC2 上で動く Elasticsearch と Kibana を AWS Elasticsearch Service (5.1) & Kibana 5 に移行するときに、ちょっとハマったポイントがあったのでメモとして残しておきます。
一部のレコードがなぜか aggregate できない
MySQL が吐くスロークエリログをいい感じにしたいとき、fluent-plugin-mysqlslowquery を利用して Elasticsearch に送り、Kibana を使って視覚化する、という常套手段があります。 このとき、以下のスクリーンショットのような感じで Split Bars の Sub Aggregation に Temrs を指定し、スロークエリの SQL 文 (sql.keyword) で棒を分割するでしょう。
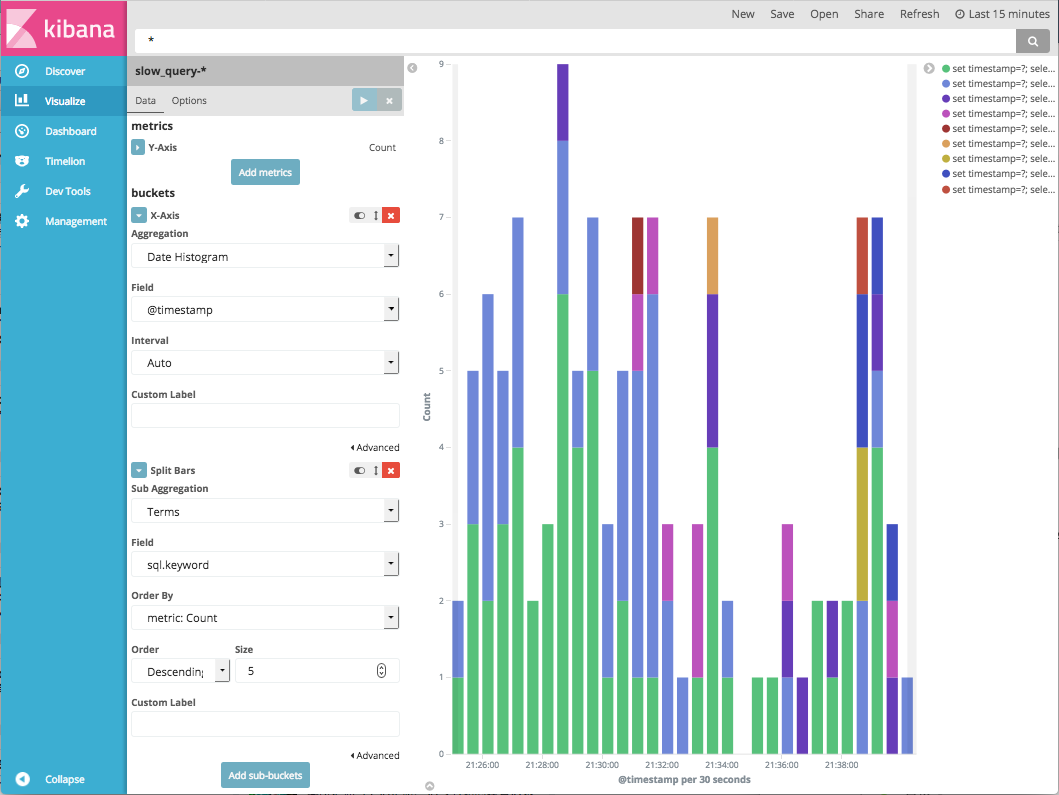
このとき、雑に fluent-plugin-mysqlslowquery を使って動的にマッピングしてレコードを投げ込むようにしていると、一部のレコードがなぜか aggregate できないという現象に悩まされることになります。
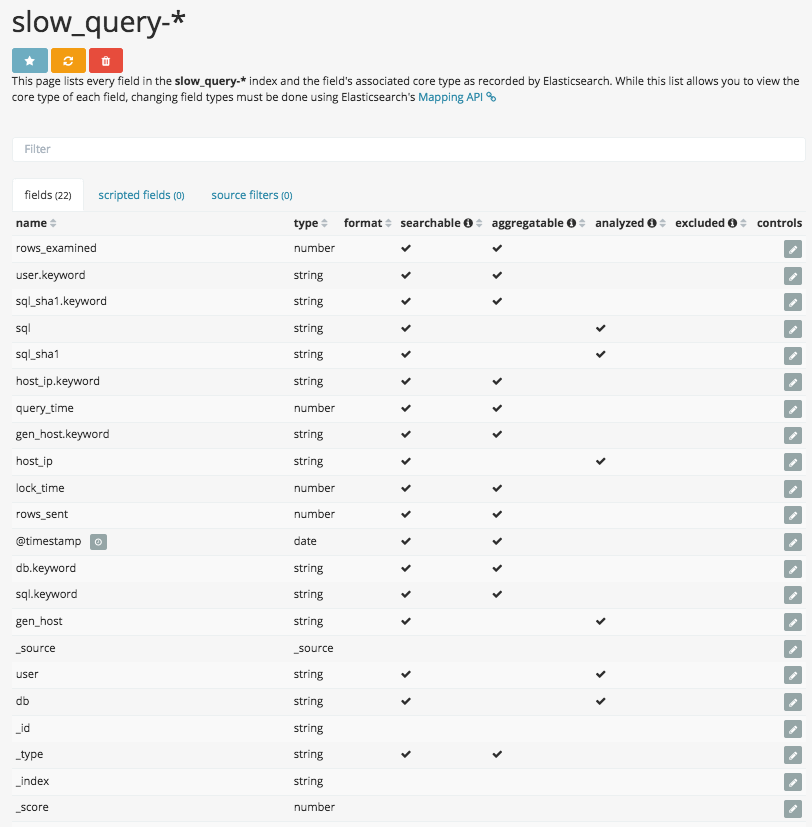
Kibana 5 の設定画面でフィールドを見てみる
なにかがおかしいということで、Kibana 5 の設定画面でフィールドの様子を見てみます。 問題の sql.keyword ですが、きちんと aggregatable にチェックがついていますね。さてどうしたものか。
マッピングを見てみる
Elasticsearch の Mapping API を使って、マッピングを確認します。
{ "slow_query-2017.06.01": { "mappings": { "query_log": { "properties": { "@timestamp": { "type": "date" }, // : // : 中略 // : "sql": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, // : // : 中略 // : } } } } }
sql.keyword の ignore_above: 256 がミソです。実は、Elasticsearch 5.x から雑に文字列を投げ込むとそれを string 型と解釈し、さらに text と keyword に分割するという挙動になっています。
参考: Strings are dead, long live strings!
このとき aggregatable になるのは sql.keyword で、ignore_above に設定されている値以上の長さを持つ文字列はインデキシングされず、ストアもされません。つまり aggregate に使うことができません。
そして、この ignore_above のデフォルト値は 256 です。なので、256 文字を超えがちな SQL 文などで aggregate しようとするとつらい感じになります。
参考: ignore_above | Elasticsearch Reference [5.1] | Elastic
どうにかするぞ
これをどうにかするには、以下のような方法が考えられます。
- サボらずにちゃんとマッピングを設定する
- index template と dynaminc mapping でデフォルト値を上書きする
理想はサボらずにちゃんとマッピングを設定することですが、節約のためにひとつの Elasticsearch クラスタにいろんなログを同居させている場合などは、ちまちまマッピングを設定するのも非現実的です。 ここでは、サボって dynaminc mapping によるデフォルト値の上書きで対処しました。
わたしは、こんな感じのテンプレートを設定しました。
{ "order": 0, "template": "*", "settings": {}, "mappings": { "_default_": { "dynamic_templates": [ { "rule1": { "mapping": { "type": "text", "fields": { "keyword": { "ignore_above": 2048, "type": "keyword" } } }, "match_mapping_type": "string", "match": "*" } } ] } }, "aliases": {} }
こうすると、全てのインデックスにおいて、文字列の keyword フィールドの ignore_above のデフォルト値が 2048 になり、長い文字列でも aggregate することができるようになります 🎉🐰👍