
Cerebro の実用的な Docker image を作った (Elasticsearch 管理のおともに)
TweetCerebro とは
Elasticsearch クラスタを運用するにあたって、REST API を使ってインデックスやクラスタそのものの操作をすることは避けられません。 その際、API の結果として返ってくる JSON だけでクラスタの状態を想像してオペレーションを行うのは、ウサギや人類には結構厳しいものがあります。
また、インフラエンジニアだけではなく、サービスエンジニアが自分たちのプロダクトで使っている Elasticsearch を責任を持って管理できるようにするためにも、使いやすい管理ツールは強力な武器となります。
Elasticsearch 5.0 以前は Kopf というプラグインが主流でしたが、site plugin が廃止されたためスタンドアロンな管理ツールが必要になります。 site plugin の廃止については以下のブログ記事が詳しいです。
Running site plugins with Elasticsearch 5.0
Kopf もスタンドアロンで動くようですが、Kopf のオリジナルの作者である @lmenezes の新作である Cerebro に置き換わる予定のようです。 業務で Docker 化して Amazon ECS に乗せて導入してみたところ、普通に実用段階でした。いますぐ Kopf を捨てて Cerebro に乗り換えましょう。
すぐに業務で使える Docker image
Cerebro が v0.5.1 のときに初めて導入し、Dockerfile は会社の GHE のリポジトリに置いていました。 現在 v0.6.1 が available なので、いい機会なのでアップデートがてら Dockerfile を OSS にしました。 ちょうどご家庭の Elasticsearch にも導入したかったので。
- GitHub: https://github.com/mozamimy/docker-cerebro
- Docker Hub: https://hub.docker.com/r/mozamimy/cerebro
使い方は、GitHub リポジトリに置いてある docker-compose.yml を見てください。
version: '3' services: cerebro: build: context: . args: ENTRYKIT_VERSION: 0.4.0 VERSION: 0.6.1 URL: 'https://github.com/lmenezes/cerebro.git' TIMEZONE: Asia/Tokyo ports: - '9000:9000' environment: # DO NOT USE this value in production environment! APPLICATION_SECRET: aifai5oosai0go=ereisiith8phaer2eegie=re9euhaengei5Xo2eiTho1Ee5Ahvae$k9 # Use SQLite3 in app container DBS_DEFAULT_DRIVER: SQLiteDriver DBS_DEFAULT_DB_DRIVER: org.sqlite.JDBC DBS_DEFAULT_DB_URL: '"jdbc:sqlite:"./cerebro.db' HOSTS: > ES1,http://es1:9200 ES2,http://es2:9200 # Show rendered application.conf to debug it # command: showconf es1: image: elasticsearch:5.2-alpine command: -E node.name="es1" -E discovery.zen.ping.unicast.hosts="es2:9300" -E transport.host="0.0.0.0" -E discovery.zen.minimum_master_nodes=1 ports: - '19200:9200' environment: ES_JAVA_OPTS: -Xms750m -Xmx750m es2: image: elasticsearch:5.2-alpine command: -E node.name="es2" -E discovery.zen.ping.unicast.hosts="es1:9300" -E transport.host="0.0.0.0" -E discovery.zen.minimum_master_nodes=1 ports: - '29200:9200' environment: ES_JAVA_OPTS: -Xms750m -Xmx750m
docker-compose.yml では例として Elasticsearch コンテナを 2 台起動してクラスタを組んでいますが、これはあくまでローカルで試すためのサンプルです。
実際には HOSTS 環境変数に対象の Elasticsearch の FQDN をプリセットとして用意する感じになると思います。
APPLICATION_SECRET には適当なランダムな文字列を秘匿値としてセットしてください。
docker-compose up すると、こんな感じでシュッと動きます。
オシャンティ〜🐰💕
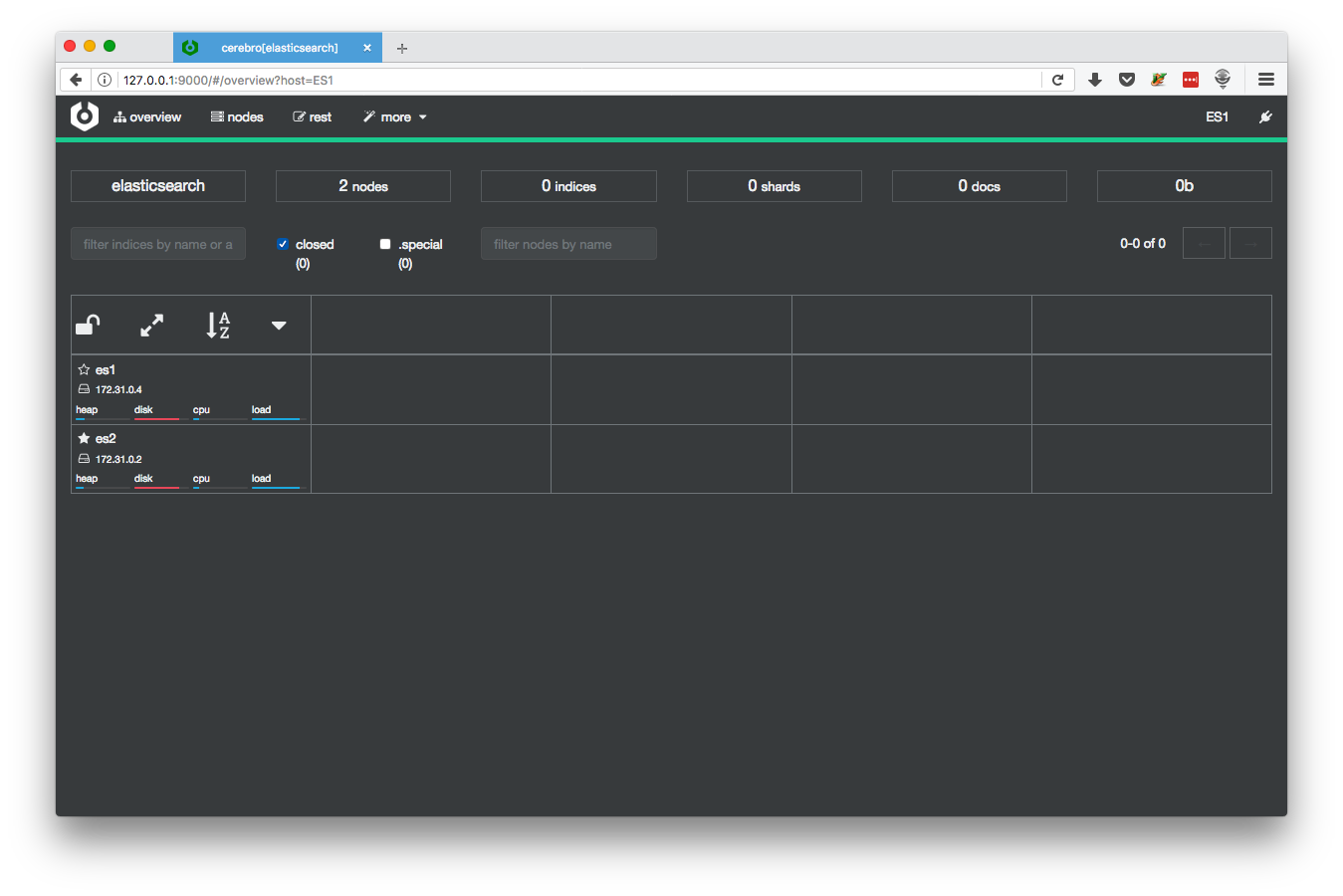
たぶん v0.6.1 からなのですが、各ノードのリソースの様子をリアルタイムで見れる画面が追加されていました。
雑記
Entrykit を使った設定ファイルのテンプレート化
設定ファイルである application.conf は Entrykit を利用してテンプレート化してあり、環境変数経由でトップ画面のリストにノードを追加できるようにしてあります。 そのため、ノードを追加するためだけに docker build する必要がなくなり、単に環境変数を書き換えてコンテナを上げ直せば反映されるようになっています。
設定ファイルで Basic 認証をかけたり LDAP の設定も可能なのですが、認証などは必要なら Cerebro の手前に用意するリバースプロキシでやればいいし、あんまりモチベーションがないのでテンプレート化していません。 わたしのモチベーションがないだけで、環境変数経由で設定できれば便利そうなのでパッチはウェルカムです。
SQLite.....
おそらく v0.6.1 からの機能で、発行した REST API リクエストの履歴を保持する機能が追加されており、履歴を保持するためのストレージとして SQLite が使われています。
これはあんまりだと思ったので、なんとか設定ファイルに MySQL のドライバを設定したりしてみたのですが、 どうも SQLite きめうちのように見える のであきらめました。
コンテナを落とせば当然履歴も消えてなくなるのですが、これはもうあきらめました。 ボリュームをマウントして Docker ホストに置くことも考えましたが、インスタンスが変われば当然意味をなさないので..
ベースイメージに java:openjdk-8u111-jre-alpine を使いたかった
見出しのとおりです。
深く追ってないので正確にはわからないですが、Java の SQLite のドライバをロードするときに Apline Linux あるあるの glibc がない問題にぶち当たり、結局 java:openjdk-8u111-jre をベースイメージにしました。
ちなみに v0.5.1 までは SQLite を使っていなかったので、java:openjdk-8u111-jre-alpine をベースイメージにできました。